
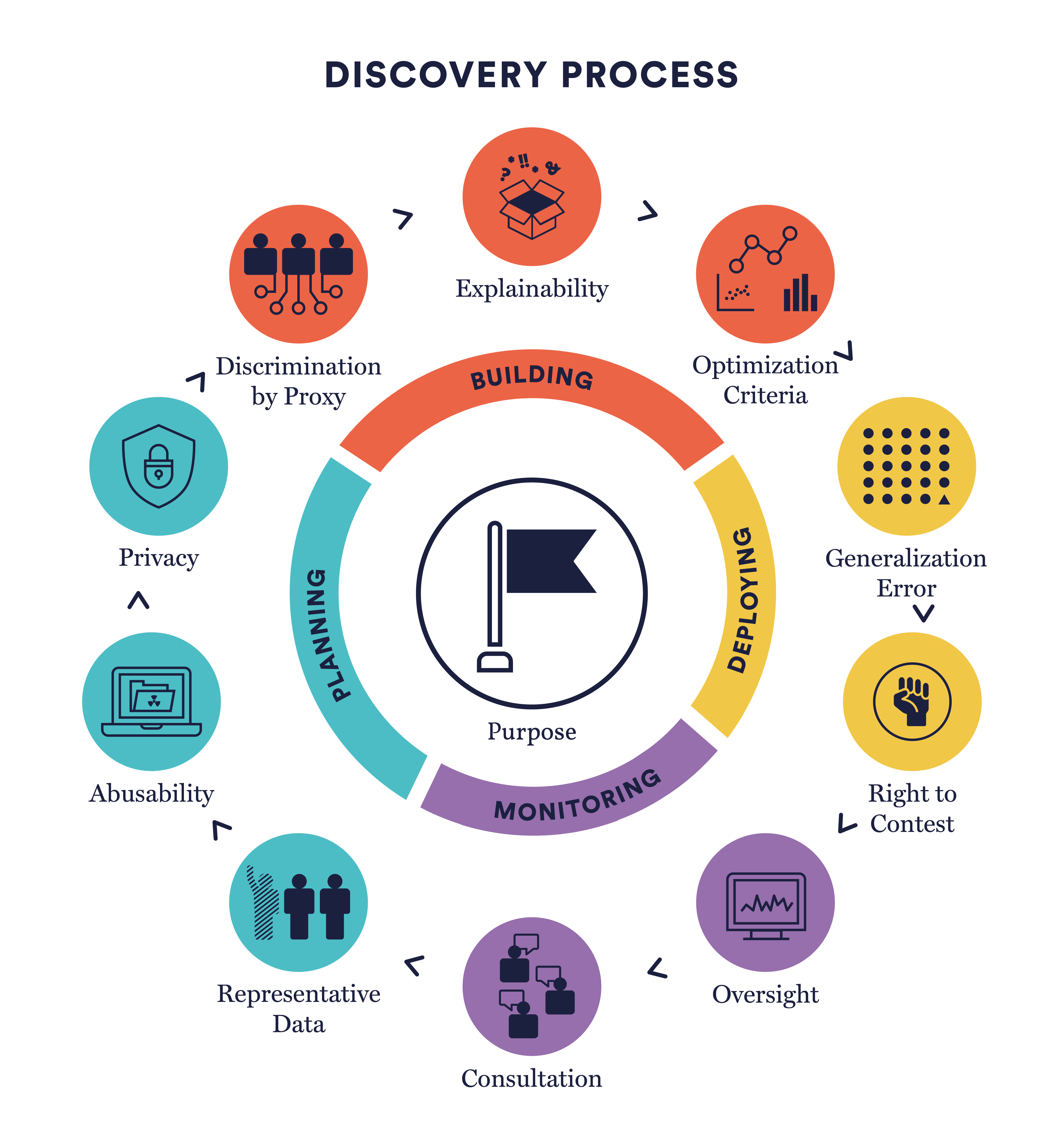



AI systems should make the world a better place. Defining a shared goal guides decisions across the lifecycle of an algorithmic decision-making system, promoting trust amongst individuals and the public.
For an algorithm to be effective, its training data must be representative of the communities that it may impact. The way that you collect and organize data will benefit certain groups while excluding or harming others.
The designers of an AI system need to anticipate vulnerabilities and dual-use scenarios by modeling how bad actors might hijack and weaponize the system for malicious activity.
AI systems often gather personal information that can invade our privacy. Systems storing confidential data can also be vulnerable to cyberattacks that result in devastating data breaches to access personal information.
An algorithm can have an adverse effect on vulnerable populations even without explicitly including protected characteristics. This often occurs when a model includes features that are correlated with these characteristics.
The technical logic of algorithms is complex, which make recommendations unclear. People involved in designing and deploying algorithmic systems have a responsibility to explain high-stakes decisions that affect individuals' well-being.
There are trade-offs and potential externalities when determining an AI system's metrics for success. It is important to balance performance metrics against the risk of negatively impacting vulnerable populations.
Between building and deploying an AI system, conditions in the world may change or not reflect the context in which the system was designed, such that training data are no longer representative.
Like any human process, AI systems carry biases that make them subjective and imperfect. The right to contest an algorithmic decision can surface inaccuracies and grant agency to people affected.
Ethical principles, standards, and policies are futile unless monitored and enforced. A diverse oversight body vested with formal authority can help to establish and maintain transparency, accountability, and sanctions.
The first, last, and every step in-between should include public participation. AI practitioners must enable meaningful input, explanations, and disclosures to ensure that AI systems promote human flourishing and mitigate harms.
Create a new card.
